
I’ve written before (1, 2, 3) about my efforts to implement a system like the one Karl Voit has for managing personal data. Voit uses his Memacs system to automatically collect data from a variety of sources and add them to Org files so that they will appear in his Org agenda. Unfortunately, Memacs was written with the Linux/Android ecosystem in mind so much of it needs a bit work to be usable in the OS X/iOS world.
Nevertheless, many of the ideas (and probably some of the scripts) from Memacs can be used with Org mode on any platform. I keep most of my personal data in 5 Org files: journal, chart (a lightweight quantified self), b-ideas (a queue of ideas and notes for blog posts), todo, and notes. I have capture templates for each of these making it easy to add data. My latest effort to make this data more accessible and useful was to modify the capture templates to add an active time stamp to each entry, causing it to appear in that day’s agenda. For example, here is the capture template for my journal:
("j" "Journal" entry (file+datetree "~/org/journal.org") "* %<%R: >%? %^g\n%t")
The %t at the end causes an active date stamp to be added to each journal entry. Thereafter, the headline and tags from the entry will appear in the agenda and selecting that headline will take me directly to the entry.
Here’s an example of one day’s agenda. If I want to know what happened on that day, I can jump directly to it in my agenda to find out. If I want to see where I’ve had dinner, I can bring up all the entries with a tag of dinner. It’s a tremendously powerful system that comes almost for free just by arranging for those active date stamps.
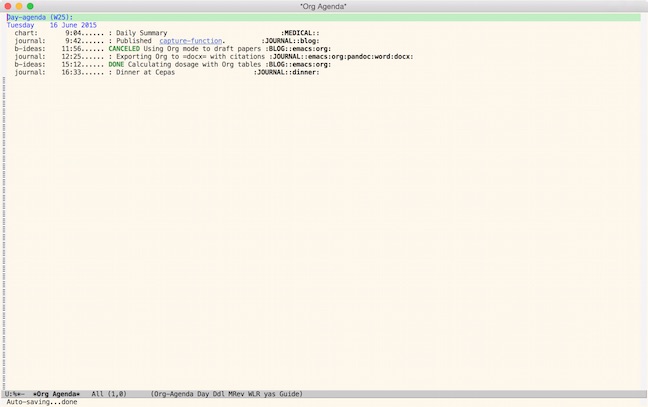
It could be better though. That’s where Memacs comes in. It automatically extracts data from SMS, the Phone’s log, posts, emails, and other data sources. All of the data magically appears in the agenda without having to explicitly capture it. My next step is to adapt some of Voit’s Memacs scripts for my own use.
All this seems pretty geeky but I use the system every day for practical tasks. This morning, for example, I used it to extract data for my tax files. If, as often happens, I find I need to make an update to a blog post, there’s a link to the source file right in the agenda and clicking on it brings up the proper file. As you can see in the example, I also add technical items to my journal. If I need to export an Org file containing citations to docx and don’t remember how, I can search for the docx tag to find the journal entry that contains the details.
Org is tremendously powerful and it pays huge dividends for the effort you expend learning it. One of the nice things about Org is you don’t have to learn everything at once. I keep learning new bits as I find a need for them.