
The Problem
While I was going through my RSS feed the other day, I came across this Programming Praxis problem and thought right away that the solution called for a state machine. It’s one of those problems that seems easy enough but if you (or, at least, I) try to write it straight out without a state machine you end up drowning in little details and inevitably get something wrong.
Later, I thought that it would serve as an excellent example of Christopher Wellons’ buffer passing style that I wrote about previously. I coded it up from memory so of course I got the problem wrong. Not just wrong but backwards. It doesn’t really matter for our purposes so the problem we’re solving is to remove any repeated instance of the target character. Thus if X is the target character, then XabXXcdXeXXXfX → XabcdXefX.
We want to write a function, remove-repeated that will take the target character and a string and remove all repeated sequences of the target character. You can see right away why it’s a perfect example of the problem Wellons was discussing: we need to build an output string piece by piece so the buffer passing style is just what we need.
The State Machine
This is a pretty simple problem so a simple state machine with three states is all we need.
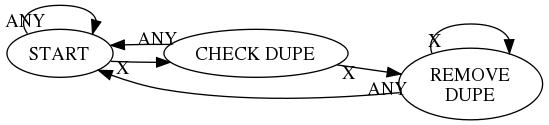
The state diagram doesn’t show any actions—see the code for that—it just lists the states and their transitions. In the diagram, X stands for the target character and ANY is any other character.
The Code
Here’s the state machine implemented in Emacs Lisp. If there were a lot of states, the case-style implementation wouldn’t be very efficient but it’s fine for our three states.
1: (defun remove-repeated (ch-to-remove string) 2: "Remove any sequence of two or more occurrences of CH-TO-REMOVE 3: from STRING." 4: (let ((state :start)) 5: (setq case-fold-search nil) 6: (dolist (current-ch (string-to-list string)) 7: (case state 8: (:start (if (char-equal current-ch ch-to-remove) 9: (setq state :check-dupe) 10: (insert current-ch))) 11: (:check-dupe (if (char-equal current-ch ch-to-remove) 12: (setq state :remove-dupe) 13: (insert ch-to-remove) 14: (insert current-ch) 15: (setq state :start))) 16: (:remove-dupe (unless (char-equal current-ch ch-to-remove) 17: (insert current-ch) 18: (setq state :start))))) 19: (when (eql state :check-dupe) 20: (insert ch-to-remove))))
The when in line 19 takes care of the case where there is a single target character at the end of the string.
When we run the code with
(with-temp-buffer (remove-repeated ?X "XabXXcdXeXXXfX") (buffer-string))
we get XabcdXefX as expected. Notice how remove-repeated doesn’t bother building a string. It just puts the required characters in the current buffer and returns. The caller coerces it into a string and the temporary buffer is killed when control flows out of the with-temp-buffer form.
To illustrate the flexibility of this approach, suppose we want to return the length of the resulting string. We could, of course, just change the last line of the call to
(length (buffer-string))
but a more efficient solution is to simply replace the last line with
(buffer-size)
and not bother forming the actual string at all.